Mesin paralel
Untuk melakukan aneka jenis komputasi paralel ini diperlukan infrastruktur mesin paralel yang terdiri dari banyak komputer yang dihubungkan dengan jaringan dan mampu bekerja secara paralel untuk menyelesaikan satu masalah. Untuk itu diperlukan aneka perangkat lunak pendukung yang biasa disebut sebagai middleware yang berperan untuk mengatur distribusi pekerjaan antar node dalam satu mesin paralel. Selanjutnya pemakai harus membuat pemrograman paralel untuk merealisasikan komputasi. Tidak berarti dengan mesin paralel semua program yang dijalankan diatasnya otomatis akan diolah secara paralel !Salah satu middleware orisinal yang dikembangkan di Indonesia adalah openPC[1] yang digawangi oleh GFTK LIPI dan telah diimplementasikan dengan di LIPI Public Cluster.
GRID[2]
GRID merupakan pengembangan teknologi mesin paralel dengan memanfaatkan jaringan pita lebar di era dijital. Dengan adanya jaringan pita lebar, paralelisasi tidak hanya dilakukan antar komputer dalam satu jaringan, tetapi juga antar mesin paralel yang terpisah secara geografis.Pemrograman Paralel
Pemrograman paralel adalah teknik pemrograman komputer yang memungkinkan eksekusi perintah/operasi secara bersamaan (komputasi paralel), baik dalam komputer dengan satu (prosesor tunggal) ataupun banyak (prosesor ganda dengan mesin paralel) CPU. Bila komputer yang digunakan secara bersamaan tersebut dilakukan oleh komputer-komputer terpisah yang terhubung dalam suatu jaringan komputer lebih sering istilah yang digunakan adalah sistem terdistribusi (distributed computing).Motivasi
Tujuan utama dari pemrograman paralel adalah untuk meningkatkan performa komputasi. Semakin banyak hal yang bisa dilakukan secara bersamaan (dalam waktu yang sama), semakin banyak pekerjaan yang bisa diselesaikan. Analogi yang paling gampang adalah, bila anda dapat merebus air sambil memotong-motong bawang saat anda akan memasak, waktu yang anda butuhkan akan lebih sedikit dibandingkan bila anda mengerjakan hal tersebut secara berurutan (serial). Atau waktu yg anda butuhkan memotong bawang akan lebih sedikit jika anda kerjakan berdua.Performa dalam pemrograman paralel diukur dari berapa banyak peningkatan kecepatan (speed up) yang diperoleh dalam menggunakan tehnik paralel. Secara informal, bila anda memotong bawang sendirian membutuhkan waktu 1 jam dan dengan bantuan teman, berdua anda bisa melakukannya dalam 1/2 jam maka anda memperoleh peningkatan kecepatan sebanyak 2 kali.
Peningkatan Kecepatan
Peningkatan kecepatan dapat diformulasikan dalam persamaan berikut ini
Dimana T1 adalah waktu yang dibutuhkan untuk menyelesaikan pekerjaan (program komputer) bila dijalankan dalam satu komputer. Dan Tj adalah waktu yang dibutuhkan jika pekerjaan dikerjakan bersamaan oleh beberapa komputer.
Ada limitasi dalam usaha membuat suatu program komputer berjalan lebih efisien melalui peningkatan kecepatan, hukum yang menetapkan batasan ini dikenal sebagai Hukum Amdahl. Ide dari hukum amdahl ini adalah bahwa anda hanya akan bisa meningkatkan efisiensi program komputer anda, sebatas pada bagian tertentu dari program tersebut yang dapat di paralelkan. Sementara bagian yang memang harus dilaksanakan secara berurutan, akan menjadi penentu performa akhir.
Kembali ke analogi memasak tadi, bila anda harus menggunakan sarung tangan sebelum menyalakan kompor ataupun memotong bawang, maka waktu yang anda butuhkan untuk memakai sarung tangan ini adalah waktu serial, yang tidak dapat dihindari. Sementara waktu untuk memasak dan memotong bawang tadi adalah bagian yang bisa diparalelkan.
Hukum Amdahl
Telah dijelaskan bahwa dari T1 (waktu yg dibutuhkan menjalankan pekerjaan dalam satu komputer) tadi, ada sebagian yg tidak bisa diparalelkan. Untuk menyatakan ini kita gunakan notasi α dimana menunjukkan berapa bagian dari T1 yang tidak bisa dijadikan paralel (atau bagian serial dari program ini).
menunjukkan berapa bagian dari T1 yang tidak bisa dijadikan paralel (atau bagian serial dari program ini).Maka kita ketahui α * T1 adalah waktu yg tidak akan terpengaruh oleh bertambahnya komputer yg digunakan (a).
Sisanya (1 − α) * T1 adalah waktu yang akan berkurang menjadi
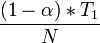 bila kita menggunakan N komputer tambahan {b) .
bila kita menggunakan N komputer tambahan {b) .Sehingga waktu total yang dibutuhkan untuk menjalankan pekerjaan dalam N komputer adalah (a) + (b) alias :



 ) komponen (b) akan dapat diabaikan, menyisakan persamaan :
) komponen (b) akan dapat diabaikan, menyisakan persamaan :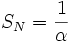
Dalam sistem terdistribusi dimana anda berusaha menggunakan lebih banyak prosesor untuk menyelesaikan masalah, akan ada imbal balik. Menggunakan komputer tambahan dari lokasi yang berbeda memberikan anda sumber komputasi baru, tapi juga melibatkan biaya komunikasi tambahan, saat anda harus memberikan pekerjaan tersebut pada komputer yg terpisah.
Bahasa populer dalam Pemrograman Paralel
- MPI Message Passing Interface, bahasa pemrograman dengan basis pertukaran pesan.
- PVM Parallel Virtual machine.
Istilah-istilah dalam pemrograman paralel
- Embarasingly Parallel adalah pemrograman paralel yang digunakan pada masalah-masalah yang bisa diparalelkan tanpa membutuhkan komunikasi satu sama lain. Sebenarnya pemrograman ini bisa dibilang sebagai pemrograman paralel yang ideal, karena tanpa biaya komunikasi, lebih banyak peningkatan kecepatan yang bisa dicapai.
- Taksonomi dari model pemrosesan paralel dibuat berdasarkan alur instruksi dan alur data yang digunakan:
- SISD Single Instruction Single Datapath, ini prosesor tunggal, yang bukan paralel.
- SIMD Single Instruction Multiple Datapath, alur instruksi yang sama dijalankan terhadap banyak alur data yang berbeda. Alur instruksi di sini kalau tidak salah maksudnya ya program komputer itu. trus datapath itu paling ya inputnya, jadi inputnya lain-lain tapi program yang digunakan sama.
- MIMD Multiple Instruction Multiple Datapath, alur instruksinya banyak, alur datanya juga banyak, tapi masing-masing bisa berinteraksi.
- MISD Multiple Instruction Single Datapath, alur instruksinya banyak tapi beroperasi pada data yang sama.
Perkembangan di Indonesia
Di Indonesia, usaha untuk membangun infrastruktur mesin paralel sudah dimulai sejak era 90-an, meski belum pada tahap serius dan permanen. Namun untuk pemrograman paralel sudah sejak awal menjadi satu mata-kuliah wajib di banyak perguruan tinggi terkait. Baru pada tahun 2005 dimulai pembuatan infrastruktur mesin paralel permanen, misalnya yang dikembangkan oleh Grup Fisika Teoritik dan Komputasi di P2 Fisika LIPI. Didorong oleh perkembangan pemrograman paralel yang lambat, terutama terkait dengan sumber daya manusia (SDM) yang menguasainya, mesin paralel LIPI ini kemudian dibuka untuk publik secara cuma-cuma dalam bentuk LIPI Public Cluster (LPC)[3]. Saat ini LPC telah dikembangkan lebih jauh menjadi gerbang komputasi GRID di Indonesia dengan kerjasama global menjadi IndoGRID.Pada tahun berikutnya, dengan dukungan dana dari proyek Inherent Dikti, Fasilkom UI juga membangun mesin paralel[4]. Sementara itu pada tahun 2009, ITB membuat kluster hibrid CPU dan GPU yang pertama di Indonesia dengan kemampuan hingga 60 inti CPU dan 1920 inti GPU.
Tidak ada komentar:
Posting Komentar